Database Relasional
Dalam database relasional, referensi baris dan tabel lain ditunjukkan dengan mengacu pada atribut utama (=primer) mereka, yang dilaksanakan dengan ketentuan bahwa koneksi tidak pernah opsional. Relasi dihitung pada saat permintaan (=query) dengan cara mencocokkan kunci primer dan banyak kunci asing(= foreign keys) yang berpotensi diindeks, dari baris tabel yang akan JOIN. Operasi ini sangat memakan tenaga CPU dan RAM dengan biaya / energi yang eksponensial.

Jika Anda menggunakan relasi banyak-ke-banyak (=many-to-many relationship), Anda harus menggunakan JOIN tabel yang berisi daftar kunci asing dari kedua tabel yang berpartisipasi yang mana akan meningkatkan biaya operasi. Proses operasi JOIN tabel ini mahal, sehingga biasanya ditangani dengan denormalisasi data untuk mengurangi jumlah JOIN tabel sebatas yang diperlukan saja.
Meskipun tidak semua use-case cocok untuk jenis model data yang ketat, kurangnya alternatif yang layak dan dukungan pada database relasional telah membuatnya menjadi sulit bagi model-model alternatif untuk masuk ke format utama (=mainstream).
Dari Database Relasional ke Database Grafik
Relasi adalah komponen utama dari model data grafik, tidak seperti sistem manajemen database lain, yang mengharuskan kita untuk menyimpulkan hubungan antara entitas dengan menggunakan properti seperti kunci asing, atau pengolahan sampingan seperti pengurangan peta. Dengan merakit abstraksi sederhana node dan relasi ke dalam struktur terhubung, database grafik memungkinkan kita untuk membangun model canggih yang memetakan model yang erat dengan domain masalah kita.
Dalam beberapa hal, database grafik seperti generasi lanjutan dari database relasional, tetapi dengan dukungan utama untuk "relasi", yaitu koneksi implisit seperti yang ditunjukkan melalui-kunci asing dalam database relasional.
Setiap node (entitas atau atribut) dalam model database grafik langsung berisi daftar catatan relasi yang mewakili hubungan ke node lain, yang diatur oleh jenis dan arah dan pemegang atribut tambahan. Setiap kali Anda menjalankan proses setara dengan operasi JOIN tabel, database memanfaatkan daftar ini dan memiliki akses langsung ke node yang terhubung, sehingga menghilangkan kebutuhan untuk proses perhitungan pencarian yang mahal.
Model yang dihasilkan lebih sederhana dan pada saat yang sama lebih ekspresif daripada yang diproduksi menggunakan database relasional dan database NoSQL lainnya.

Tidak seperti database NoSQL lainnya, database grafik mendukung model data yang sangat fleksibel dan halus yang memungkinkan Anda untuk membuat model dan mengelola domain dengan cara yang mudah dan intuitif.
Anda lebih kurang menyimpan data seperti di dunia nyata: kecil, normal, namun sangat terkait dengan entitas. Hal ini memungkinkan Anda untuk meminta (=query) dan melihat data Anda dari sudut pandang yang mudah dibayangkan, serta mendukung banyak use-case yang berbeda.
Model halus juga berarti bahwa tidak ada batasan natural sekitar agregat, sehingga ruang lingkup operasi update bisa dilaksanakan oleh aplikasi. Konsep kelompok transaksi yang terkenal dan teruji untuk update satu set node dan relasi menjadi operasi ACID (= atomik, konsisten, terisolasi dan tahan lama). Database grafik seperti Neo4j sepenuhnya mendukung konsep transaksional termasuk tulis-dulu log, dan pemulihan data dalam kasus terminasi abnormal.

Jika Anda terbiasa pemodelan dengan database relasional, cobalah untuk mengingat kemudahan dan keindahan dari normalisasi diagram relasi entitas: cara yang sederhana dan mudah untuk menggambarkan dan memahami model Anda dapat dengan cepat bersama rekan-rekan Anda dan para ahli domain.
Mari kita buat model yang realistis dari domain organisasi dan menunjukkan bagaimana hal itu akan dimodelkan dalam database relasional vs database grafik, sebagai berikut:
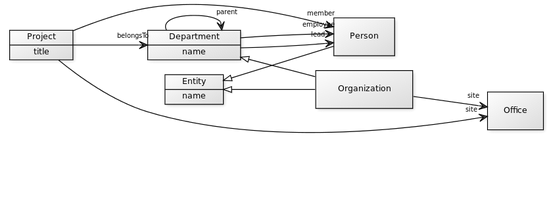
Query pada Database Grafik Menggunakan Cypher
Query database relasional dengan mudah dilakukan menggunakan bahasa query deklaratif pada SQL yang memungkinkan query ad-hoc pada database, serta menentukan query terkait use-case dalam kode Anda. Bahkan pemeta objek-relasional menggunakan SQL untuk langsung berbicara dengan database.
Apakah database grafik memiliki sesuatu yang mirip? Cypher, bahasa query grafik deklaratif Neo4j, dibangun di atas konsep-konsep dasar dan klausa SQL tetapi memiliki banyak tambahan fungsi-grafik khusus untuk membuatnya mudah untuk bekerja dengan model grafik yang kaya tanpa terlalu bertele-tele.
Jika Anda pernah mencoba untuk menulis pengkodean SQL dengan banyak JOIN tabel, Anda tahu bahwa Anda dengan cepat bisa kehilangan arah sebenarnya karena semua kesibukan teknis yang tidak perlu.
Dalam domain organisasi pada gambar di atas, bagaimana pengkodean SQL yang berisi daftar karyawan di "Departemen IT" terlihat, dan bagaimana pengkodean SQL bila dibandingkan dengan pengkodean Cypher?
SQL Statement
SELECT * FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "IT Department"
Cypher Statement
MATCH (p:Person)<- d:department="" font="">
WHERE d.name = "IT Department"
RETURN p.name
Mengimpor Data dari Database Relational
Jika Anda memiliki pemahaman yang baik tentang apa model grafik Anda akan terlihat, yaitu data apa yang akan direpresentasikan sebagai node atau relasi, dan bagaimana label, relasi-jenis, dan atribut yang akan diberi nama, Anda siap untuk memulai.
Cara termudah untuk mengimpor data dari database relasional Anda adalah untuk membuat file CSV baik tabel individu dan tabel gabungan, atau dari gabungan lainnya. Maka , denormalisasi representasi.
Kemudian Anda dapat mengambil file CSV dan menggunakan perangkat CSV LOAD Cypher untuk:
- Menelan data, mengakses kolom dengan nama header atau offset
- Mengkonversi nilai dari string ke format lain dan struktur yang berbeda (toFloat, split, ...)
- Loncat baris untuk mengabaikan
- MATCH Node berdasarkan pencarian atribut
- CREATE atau MERGE node dan hubungan dengan label dan atribut dari data baris
Misalnya:
persons.csv
name;email;dept
"Lars Higgs";"lars@higgs.com";"IT-Department"
"Maura Wilson";"maura@wilson.com";"Procurement"
LOAD CSV FROM 'file:///data/persons.csv' WITH HEADERS AS line
FIELDTERMINATOR ";"
MERGE (person:Person {email: line.email}) ON CREATE SET p.name = line.name
MATCH (dep:Department {name:line.dept})
CREATE (person)-[:EMPLOYEE]->(dept)
Anda dapat mengimpor beberapa file CSV dari satu atau lebih sumber data untuk memperkaya model domain inti Anda dengan informasi lain yang mungkin menambah wawasan dan kemampuan yang menarik.
Catatan: informasi ini disarikan dari laman http://neo4j.com/developer/graph-db-vs-rdbms/
Tidak ada komentar:
Posting Komentar