Pemanfaatan Database

Sistem Database Lumen bisa dimanfaatkan untuk beberapa kebutuhan, antara lain:
- Journal and Emailed Facts, yaitu membuat jurnal bulanan dan mingguan dari kegiatan Robot Lumen sesuai kebutuhan pengguna dan administrator yang bisa diemail kepada list yang ditentukan oleh Administrator. Jurnal ini mencakup:
- Sejumlah data yang tertangkap dari kamera, microphone, berbagai sensor sentuhan, sonar, dll. Data yang tertangkap ini disimpan dan dilaporkan dalam bentuk teks.
- Rekaman gambar dan suara orang-orang, serta gambar obyek-obyek, baik yang sudah dikenali atau baru ditemui. Rekaman gambar dan suara disimpan dalam format yang sudah terkompresi
- Tugas-tugas yang dikerjakan berdasarkan perintah administrator dan permintaan para pengguna. rekaman tugas ini disimpan dalam bentuk teks
- Rekaman respon audio dari Robot terhadap pertanyaan dan permintaan para pengguna. Rekaman tanya jawab dan diskusi ini disimpan dalam bentuk teks
- Juga termasuk rekaman berbagai postur tubuh dan kondisi aktuator penggerak badan Robot. Rekaman postur dan kondisi aktuator disimpan dalam bentuk teks.
- Persistence Query and Facts, yaitu menampilkan jawaban berdasar fakta dari berbagai pertanyaan administrator atau pengguna. Fakta yang disajikan adalah fakta yang sudah terverifikasi oleh administrator maupun komunitas Wikipedia. Fakta ini bisa disajikan lewat aplikasi yang berjalan di handphone dan web browser, seperti yang terlihat pada bagian akhir dari artikel part-2. Adapun mekanismenya adalah sebagai berikut:
- Pengguna bisa memilih dari beberapa alternatif query yang tersedia. Dan dalam hitungan mili-detik, jawaban akan tersedia.
- Pengguna juga bisa mengajukan pertanyaan berdasarkan kombinasi beberapa kata kunci yang tersedia. Dan dalam hitungan mili-detik, jawaban akan tersedia.
- Alternatif lainnya, pengguna bisa juga menggunakan pertanyaan dalam bahasa natural, Bila tidak ada fakta yang bisa disajikan, maka aplikasi database bisa menanyakan alternatif pertanyaan, atau minta pertanyaan lain yang bisa terjawab.
- Lumen Social Expression, yaitu informasi terkini berbentuk ekspresi sosial yang diposting secara rutin di beberapa media sosial yang dimiliki Robot Lumen, seperti Twitter dan Facebook. Aplikasi yang mendukung fungsi ini akan segera dikembangkan dan bukan menjadi tugas utama saya. Informasi ini diharapkan akan membentuk persepsi sosial terhadap Robot Lumen. Komunikasi lewat media sosial ini direncanakan akan menjadi komunikasi dua arah, yang bisa berfungsi untuk menanyakan fakta yang tersimpan di dalam database.
- Natural Language Expression, yaitu ekspresi tanya jawab dalam bahasa natural seperti hanya percakapan antar manusia normal, sehingga Robot Lumen bisa berbicara kepada pengguna dan manusia lainnya sebagai teman yang cerdas dan baik hati. Aplikasi yang mendukung fungsi ini akan dikembangkan dalam waktu dekat dan bukan menjadi tanggungjawab saya. Aplikasi ini menjadi wajib bila Lumen akan diturunkan sebagai pemandu pameran yang bisa bicara interaktif dan bisa ditanya apa saja terkait pameran maupun beberapa hal umum lainnya.
Sumber Data
Seperti hanya seorang manusia yang belajar dari interaksi dengan lingkungan dan kegiatan yang dialaminya, Robot Lumen pun harus bisa melakukan hal yang sama. Sebagai penyimpan kecerdasan Robot Lumen, sistem database ini harus adaptif terhadap kegiatan dan lingkungan sekitar, ini adalah sumber data utama. Untuk itu Robot Lumen dilengkapi dengan sebuah Streaming Server.

Streaming server ini akan menyalurkan semua data yang ditangkap oleh semua sensor yang ada pada Robot Lumen yang tergambar dalam skematik berikut:

Terhitung ada 2 kamera, 2 microphone, 5 sensor tekanan, 2 sensor sonar, ditambah sensor-sensor gerakan pada setiap motor aktuator dan persendian yang mengendalikan 25 derajat kebebasan Robot Lumen ini, sebagaimana bisa dilihat pada gambar berikut

Namun belajar hanya mengandalkan pada pengalaman pribadi Robot Lumen akan memakan waktu terlalu lama, sehingga saya akan menambahkan sejumlah data yang saya entri sendiri, dan juga mengimpor data tambahan berkelas dunia yang sudah diverifikasi oleh Wikipedia lewat format database Yago 2, sehingga Robot Lumen bisa menjawab berbagai pertanyaan yang datanya sudah tersedia di Wikipedia.
Standar Database Lumen
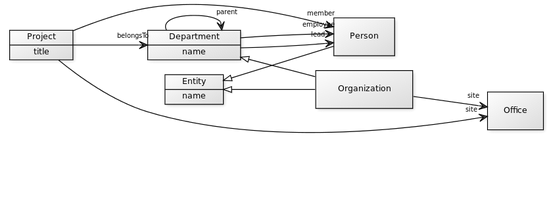
Database Lumen ini dibuat dengan menggunakan skema database khas Lumen, namun juga dengan mengadaptasi berbagai standar database berkelas dunia sehingga tidak harus menemukan hal yang sudah ditemukan orang lain, dan bisa menghemat waktu pengembangan. Adapun skema ontologi yang kita adopsi adalah sebagai berikut
Terhitung ada 144 property untuk database khas Lumen, dimana 9 adalah properti database dasar, 7 properti database spesifik Lumen, 6 properti database spesifik vCard, dan selebihnya adalah database spesifik Wiki/Yago.
Sebagian dari skema database Lumen bisa dilihat pada gambar berikut

Saat ini total ukuran dari database untuk Penyimpan kecerdasan Lumen sudah sekitar 13GB. Detail dari database dan skema database Lumen ini bisa dibagi untuk kepentingan riset atas seijin grup LSKK Prodi Teknik Elektro ITB. Bila anda berminat untuk bekerjasama, silahkan hubungi penulis untuk alamat dropbox share.